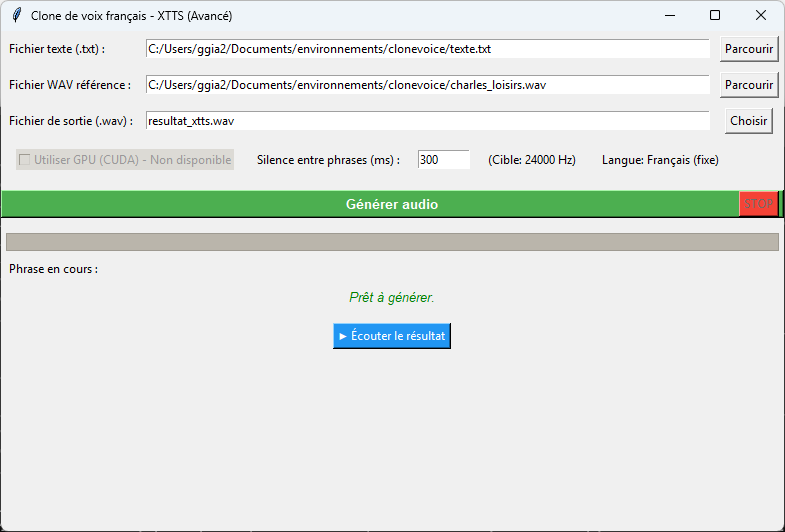
🌟 Aperçu du Projet
Le script cv6.py implémente une application de clonage de voix basée sur la librairie TTS de Coqui, utilisant spécifiquement le modèle XTTS-v2 pour la synthèse vocale multilingue. L’application est construite avec Tkinter pour fournir une interface utilisateur graphique (GUI) conviviale, permettant de générer de l’audio à partir d’un fichier texte et d’un échantillon vocal de référence.
Elle inclut des fonctionnalités avancées comme la gestion de la configuration, le multithreading pour la génération audio, l’utilisation optionnelle du GPU (CUDA), et le traitement audio (rééchantillonnage, ajout de silence, normalisation). La langue cible est fixée au Français (fr).
⚙️ Prérequis et Configuration
1. Environnement
Ce script nécessite Python 3.x et plusieurs librairies.
2. Installation des Librairies
Tu dois installer les dépendances suivantes dans ton environnement Python :
Note importante : Le paquet
TTS(ettorch) est lourd et peut prendre du temps à télécharger, car il inclut le modèle XTTS-v2 qui sera téléchargé lors de la première utilisation. Si tu souhaites utiliser le GPU, assure-toi d’avoir la version detorchcompatible avec ton installation CUDA.
3. Fichier de Configuration
Le programme crée et utilise automatiquement un fichier de configuration nommé xtts_config.ini pour sauvegarder les chemins de fichiers et les réglages de l’interface (comme l’utilisation du GPU et la géométrie de la fenêtre).
🚀 Utilisation de l’Application (GUI)
Le script est exécuté comme une application autonome :
L’interface utilisateur permet de réaliser les étapes suivantes :
- Fichier texte (.txt) :
- Clique sur « Parcourir » pour sélectionner un fichier texte (
.txt) contenant le script à lire. - Chaque phrase se terminant par un point (
.), un point d’interrogation (?) ou un point d’exclamation (!) sera traitée individuellement.
- Clique sur « Parcourir » pour sélectionner un fichier texte (
- Fichier WAV référence :
- Clique sur « Parcourir » pour sélectionner un fichier audio WAV (
.wav) de la voix que tu souhaites cloner. - Recommandation : La durée de l’échantillon doit idéalement être comprise entre 3 et 120 secondes. Le fichier sera rééchantillonné automatiquement à 24000 Hz si nécessaire.
- Clique sur « Parcourir » pour sélectionner un fichier audio WAV (
- Fichier de sortie (.wav) :
- Spécifie le nom du fichier de sortie (
.wav). - Clique sur « Choisir » pour spécifier un emplacement et un nom de fichier différents.
- Spécifie le nom du fichier de sortie (
- Options Avancées :
- Utiliser GPU (CUDA) : Coche cette case pour utiliser le GPU pour la génération, si
torchdétecte une carte compatible. Ceci accélère considérablement la génération. - Silence entre phrases (ms) : Règle la durée du silence ajouté entre chaque phrase générée (valeur par défaut : 300 ms).
- Utiliser GPU (CUDA) : Coche cette case pour utiliser le GPU pour la génération, si
- Actions :
- « Générer audio » : Démarre le processus de clonage de voix dans un thread séparé.
- « STOP » : Permet d’annuler une génération en cours.
- « ▶ Écouter le résultat » : Lance la lecture du fichier de sortie généré (nécessite la librairie
simpleaudio).
🧱 Structure du Code et Composants Clés
1. Variables Globales
| Variable | Description | Valeur par Défaut |
MODEL_NAME | Chemin du modèle XTTS-v2 à utiliser. | "tts_models/multilingual/multi-dataset/xtts_v2" |
SPEAKER_SAMPLE_RATE | Fréquence d’échantillonnage cible pour la voix de référence et la sortie. | 24000 Hz |
MIN_REF_DURATION | Durée minimale recommandée pour le fichier de référence. | 3.0 s |
GPU_AVAILABLE | Vérifie si CUDA (GPU) est disponible. | torch.cuda.is_available() |
2. Fonctions de Génération (Logique Métier)
start_generation_thread: Lance la tâche de génération dans un thread séparé pour éviter de bloquer l’interface.stop_generation: Permet l’annulation de la tâche via un flag (self.stop_flag).generate_audio_task:- Initialise et charge le modèle XTTS (une seule fois).
- Rééchantillonne le fichier de référence à 24000 Hz si sa fréquence est différente.
- Divise le fichier texte en phrases distinctes.
- Génère l’audio phrase par phrase, en les concaténant avec des segments de silence. La langue est fixée à Français (
language="fr"). - Normalise le volume du fichier audio final avant l’exportation.
- Fournit une estimation du temps restant et met à jour la progression dans la GUI.
_cleanup_on_finish: Supprime le dossier temporaire (./temp_tts_files) une fois la tâche terminée ou annulée.
💡 Conseils d’Implémentation et Outils
1. Amélioration de la Qualité
- Qualité de la référence : Le succès du clonage dépend fortement de la qualité (pas de bruit de fond, pas de musique) et de la cohérence de la voix dans le fichier WAV de référence.
- Révision du texte : Assure-toi que le fichier texte est correctement ponctué. La division des phrases par l’expression régulière dépend des signes de ponctuation.
2. Conversion MP3 vers WAV (24000 Hz, Mono)
Pour garantir un format idéal pour le fichier de référence, tu peux utiliser FFmpeg pour convertir des fichiers MP3 (ou autres) vers un fichier WAV mono avec un taux d’échantillonnage de 24000 Hz.
Commande FFmpeg :
| Option | Description |
-i input_reference.mp3 | Spécifie le fichier d’entrée (ton fichier MP3). |
-ac 1 | Force le nombre de canaux audio à 1 (canal mono). |
-ar 24000 | Force le taux d’échantillonnage (sample rate) à 24000 Hz. |
output_reference_24k_mono.wav | Spécifie le fichier de sortie au format WAV. |