
Cette documentation détaille le processus de création de vidéos karaoké professionnelles en combinant l’intelligence artificielle pour la séparation des sources Ultimate Vocal Remover (UVR) et la génération automatisée de sous-titres synchronisés (Script Python).
L’idée de base est de convertir automatiquement un fichier MP3 en fichier karaoké MP4.
Les tests ont été réalisés avec succès sous Windows 11.
1. Phase d’Extraction : Ultimate Vocal Remover (UVR)
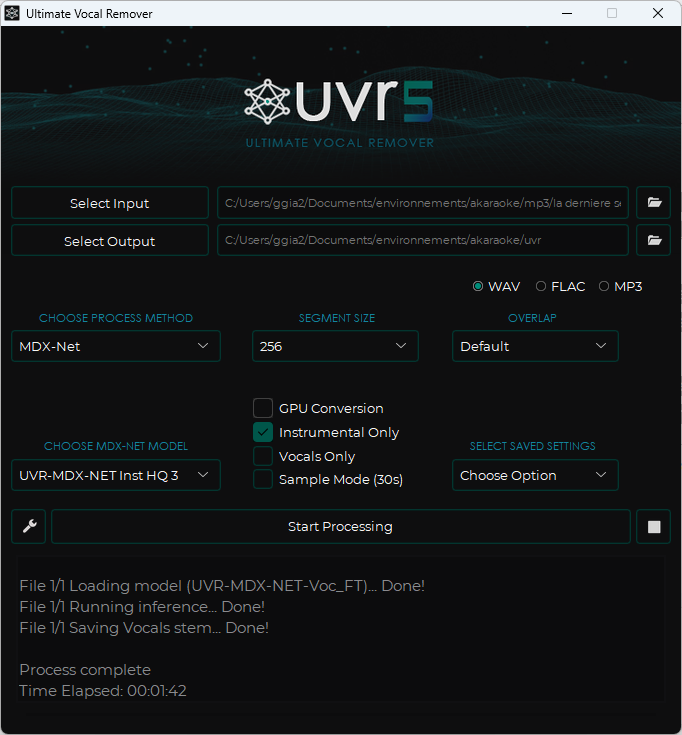
La qualité d’un karaoké dépend avant tout de la propreté de la séparation entre la voix et l’instrumentale. UVR est l’outil de référence utilisant des modèles de réseaux de neurones profonds.
Choix des Modèles Recommandés
Pour obtenir les meilleurs résultats, nous préconisons l’utilisation de l’architecture MDX-NET avec les modèles suivants :
- Pour l’Instrumentale :
UVR-MDX-NET Inst HQ3- Pourquoi : Ce modèle est optimisé pour préserver la dynamique musicale et minimiser les artefacts « fantômes » de voix dans la piste musicale.
- Pour les Voix :
UVR-MDX-NET-Voc_FT- Pourquoi : Le « Voc_FT » (Fine-Tuned) offre une clarté exceptionnelle sur les fréquences vocales, ce qui est crucial pour que l’IA de transcription (Whisper) puisse analyser précisément chaque syllabe.
L’importance du format WAV
Il est impératif d’exporter vos fichiers depuis UVR au format WAV (PCM 16/24-bit) plutôt qu’en MP3 :
- Absence de compression : Le MP3 élimine des fréquences subtiles dont l’IA a besoin pour une synchronisation parfaite.
- Précision temporelle : Les fichiers WAV garantissent qu’aucun décalage (jitter) n’est introduit lors du rendu FFmpeg.
2. Phase de Génération : Karaoké Generator Pro
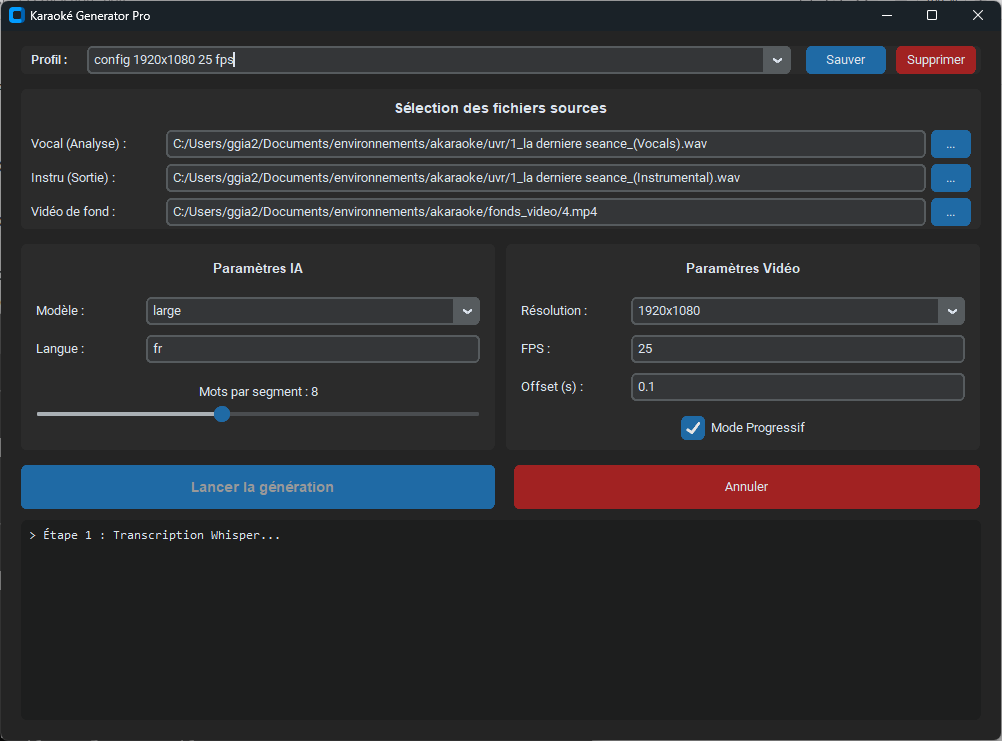
Une fois vos fichiers .wav extraits (une piste vocal.wav et une piste instru.wav), le script prend le relais pour transformer ces données en une vidéo finale.
Pourquoi utiliser ce script après UVR ?
- Transcription Automatisée : Utilise
stable-whisperpour une détection ultra-précise du texte à partir de la piste vocale isolée. - Synchronisation Syllabique : Le script calcule le timing exact de chaque mot pour créer l’effet de remplissage progressif (balises
\k) typique du karaoké professionnel. - Rendu Tout-en-Un : Il fusionne automatiquement l’audio instrumental, les sous-titres ASS et une vidéo de fond via FFmpeg.
3. Guide d’utilisation du Script
Interface et Paramètres
- Sélection des fichiers :
- Vocal : Indiquez la piste voix extraite par UVR (sert à l’analyse du texte).
- Instru : Indiquez la piste musique (sera l’audio de la vidéo finale).
- Fond : Optionnel. Si vide, le fond sera noir.
- Configuration IA :
- Modèle :
largeest recommandé pour une précision maximale,mediumpour plus de rapidité. - Mots par segment : Ajustez (entre 5 et 10) pour contrôler la densité de texte à l’écran.
- Modèle :
- Paramètres Vidéo :
- Offset : Permet d’ajuster la synchronisation globale (ex: 0.1s) pour compenser la latence naturelle de l’IA.
- Mode Progressif : Active l’animation de couleur sur les lettres au fur et à mesure du chant.
Gestion des Profils
Le script permet de sauvegarder vos réglages (résolution, FPS, modèle) sous forme de Profils. Cela est idéal pour basculer rapidement entre un format « YouTube » (1920×1080) et un format « TikTok/Shorts » (1080×1920).
4. Conseils pour un rendu optimal
- Nettoyage préalable : Si la chanson comporte des choeurs très forts, UVR peut parfois hésiter. N’hésitez pas à utiliser le modèle
UVR-MDX-NET-Voc_FTune seconde fois sur la piste vocale extraite pour l’épurer davantage. - Vérification des Logs : La console intégrée au script affiche en temps réel le temps de transcription et de rendu. Si FFmpeg échoue, vérifiez que les chemins de fichiers ne contiennent pas de caractères spéciaux exotiques.
- Hardware : La génération avec le modèle
largede Whisper est gourmande. Une carte graphique (GPU) compatible CUDA accélérera considérablement le processus.
Pour faire fonctionner le script Karaoké Generator Pro et l’intégration avec UVR, vous devez configurer un environnement Python avec plusieurs bibliothèques spécifiques.
Voici la liste des commandes à exécuter dans votre terminal pour installer les dépendances nécessaires :
5. Installation des dépendances Python (Pip)
Ouvrez votre terminal (ou invite de commande) et exécutez la commande suivante :
6. Dépendance Système : FFmpeg (Indispensable)
Le script utilise subprocess pour appeler FFmpeg, l’outil qui fusionne l’audio, la vidéo et les sous-titres. Il ne s’installe pas via pip.
- Téléchargement : Allez sur ffmpeg.org.
- Configuration : Assurez-vous que le dossier
binde FFmpeg est ajouté à votre PATH système (variables d’environnement). - Vérification : Tapez
ffmpeg -versiondans un terminal. Si une description s’affiche, le script fonctionnera.
7. Configuration pour l’accélération GPU (Optionnel)
Si vous possédez une carte graphique NVIDIA, l’extraction et la transcription seront beaucoup plus rapides. Pour cela, vous devez installer une version de PyTorch compatible avec CUDA.
Rendez-vous sur pytorch.org pour obtenir la ligne de commande spécifique à votre version de CUDA, qui ressemble généralement à ceci :
8. Structure des dossiers
Le script s’attend à pouvoir créer et lire dans certains répertoires spécifiques. Assurez-vous d’avoir les droits d’écriture dans le dossier du script. Il créera automatiquement :
uvr/: Pour stocker les fichiers.ass.uvr/mp4/: Pour les vidéos finales.
9. Vidéos de fonds
Pour parfaire l’aspect visuel de vos créations, le choix du fond vidéo est crucial. Voici comment optimiser cette étape pour obtenir un rendu professionnel avec votre script.
Choix des fonds : Vidéos en boucle (Loops)
L’utilisation de boucles vidéo permet de maintenir une dynamique visuelle sans détourner l’attention des paroles du karaoké.
Où trouver des fonds de qualité ?
Par exemple, le site Pixabay est une ressource excellente pour télécharger des contenus libres de droits. Pour des vidéos qui s’adaptent parfaitement au rythme de la musique, nous vous recommandons d’effectuer la recherche suivante :
- Lien direct : Pixabay – Abstract Motion Graphics Loop
- Mots-clés suggérés : « abstract motion graphics loop song », « VJ loop », « particle background » ou « geometric rhythm ».
Pourquoi privilégier ces termes de recherche ?
- Neutralité visuelle : Les graphismes abstraits ne contiennent pas d’éléments narratifs qui pourraient entrer en conflit avec le sens de la chanson.
- Adaptabilité : Ces vidéos n’ont généralement pas de « haut » ou de « bas » marqué, ce qui facilite leur utilisation en format paysage (16:9) ou portrait (9:16 pour TikTok/Shorts).
- Fluidité : Le terme « loop » garantit que le script peut répéter la vidéo indéfiniment sans saut d’image visible si la chanson est plus longue que le clip.
Intégration technique dans le script
Votre script gère intelligemment ces fichiers grâce à l’argument -stream_loop -1 de FFmpeg.
Fonctionnement de la boucle
- Répétition infinie : Même si vous téléchargez une boucle de 10 secondes sur Pixabay, le script la répétera automatiquement pour couvrir toute la durée de votre piste audio instrumentale.
- Ajustement automatique : Le script applique un filtre de mise à l’échelle (
scale) et de recadrage (crop) pour s’assurer que la vidéo de fond remplit parfaitement la résolution choisie (ex: 1920×1080), évitant ainsi les bandes noires.
Conseil pratique
Lors du téléchargement sur Pixabay, privilégiez le format MP4 en résolution 1080p (HD). Une fois le fichier récupéré, renseignez simplement son emplacement dans le champ « Vidéo de fond » de l’interface KaraokeApp avant de lancer la génération.
Conclusion : Vers une Création de Karaoké Semi-Automatisée et Professionnelle
L’alliance entre la puissance de séparation des sources de Ultimate Vocal Remover et l’automatisation de la synchronisation syllabique via Karaoké Generator Pro offre un flux de travail complet, rapide et de haute fidélité. En exploitant des modèles spécialisés comme UVR-MDX-NET Inst HQ3 pour l’instrumentale et UVR-MDX-NET-Voc_FT pour l’analyse vocale, l’utilisateur s’assure d’une base technique solide. L’utilisation du format WAV et l’intégration de fonds visuels dynamiques provenant de plateformes comme Pixabay permettent de transformer de simples fichiers audio en vidéos prêtes pour la diffusion.
Possibilités d’améliorations et d’extensions
Bien que le script fourni soit robuste, plusieurs axes peuvent être explorés pour enrichir l’expérience utilisateur et la qualité esthétique :
- Personnalisation Avancée des Styles ASS :
- Modifier le script pour permettre à l’utilisateur de choisir ses propres polices, couleurs et effets de bordure directement depuis l’interface graphique.
- Ajouter des animations de transition pour l’apparition et la disparition des segments de texte.
- Optimisation du Rendu Vidéo :
- Assombrissement automatique : Intégrer un filtre FFmpeg (ex:
drawboxouoverlay) pour appliquer un voile noir transparent sur le fond vidéo, améliorant ainsi le contraste et la lisibilité des paroles. - Prévisualisation en direct : Ajouter un lecteur vidéo léger dans le script pour vérifier la synchronisation sans attendre le rendu complet.
- Assombrissement automatique : Intégrer un filtre FFmpeg (ex:
- Intelligence Artificielle et Post-traitement :
- Détection automatique de la langue : Laisser Whisper détecter la langue source pour automatiser encore davantage le processus.
- Nettoyage automatique des fichiers : Intégrer un script de post-traitement audio pour normaliser le volume de la piste instrumentale avant le rendu final.
- Extensions Multi-plateformes :
- Ajouter des préréglages de résolution spécifiques pour les réseaux sociaux, comme le format 9:16 (1080×1920) avec un recadrage intelligent du fond vidéo pour les Shorts ou TikTok.