Introduction
Ce projet est un serveur centralisé d’intelligence artificielle conçu pour être exécuté sur un réseau local (LAN). Il permet aux autres machines du réseau d’envoyer des requêtes vers des modèles d’IA (LLM, Génération d’images, Vision) de manière asynchrone, grâce à une file d’attente FIFO persistante (SQLite).
Fonctionnalités Principales
Dashboard Web Complet
Le serveur intègre une interface web riche et ergonomique accessible directement via votre navigateur :
- Agencement dynamique : 3 panneaux redimensionnables (Requête, Résultat, File d’attente).
- Monitoring Matériel : Affichage en temps réel du CPU, RAM, GPU (utilisation et VRAM) et des températures.
- Mode Conversation (Mémoire) : Permet de conserver le contexte de la discussion avec le LLM.
- Support Multimodal & Fichiers :
- Upload d’images pour LLaVA (Vision) ou Stable Diffusion (Img2Img).
- Bouton ou « Glisser-Déposer » pour intégrer rapidement un script (
.py,.js, etc.) ou un fichier texte dans votre prompt. - Historique et Favoris : Gardez une trace de vos anciennes générations, mettez vos meilleurs résultats en favoris (⭐) et purgez le cache facilement.
- Confort de lecture : Coloration syntaxique automatique du code généré, boutons « Copier le code », bouton « Télécharger en .txt », et choix du Thème (Clair ☀️ / Sombre 🌙).
- Raccourcis : Soumission rapide via
Ctrl+Entrée.
Backend & API
- API REST robuste propulsée par FastAPI.
- File d’attente FIFO gérée par un worker en arrière-plan avec persistance SQLite (auto-migration incluse).
- Ollama Intégré : Exécution de LLM locaux en streaming simulé, sans limite stricte de tokens générés.
- SDK Client Python pour une intégration facile dans vos propres scripts.
Installation
Prérequis
- Python 3.10+
- Ollama installé localement et en cours d’exécution.
- Les modèles LLM téléchargés via Ollama (ex:
ollama run llama3).
Dépendances
pip install -r requirements.txt(Note : le premier appel au modèle d’image téléchargera les poids volumineux depuis HuggingFace).
Démarrage du serveur
Lancez simplement le fichier principal :
python main.pyL’application web et l’API seront accessibles sur : http://127.0.0.1:8000
(N’oubliez pas d’autoriser le port 8000 ou le binaire Python dans le pare-feu de Windows pour y accéder depuis le réseau).
Utilisation via le SDK Python
from ai_client import LocalAIClient
client = LocalAIClient(endpoint="http://127.0.0.1:8000")
# Génération de texte
result = client.generate_text("llama3", "Explique-moi la théorie de la relativité en une phrase.")
print("Texte :", result)
# Génération d'image
image_path = client.generate_image("stable-diffusion", "A futuristic city in the night")
print("Image enregistrée dans le serveur à :", image_path)
# Consulter la file d'attente
queue_status = client.get_queue_status()
print("File d'attente :", queue_status)Guide d’Utilisation : Interface Web du Serveur IA
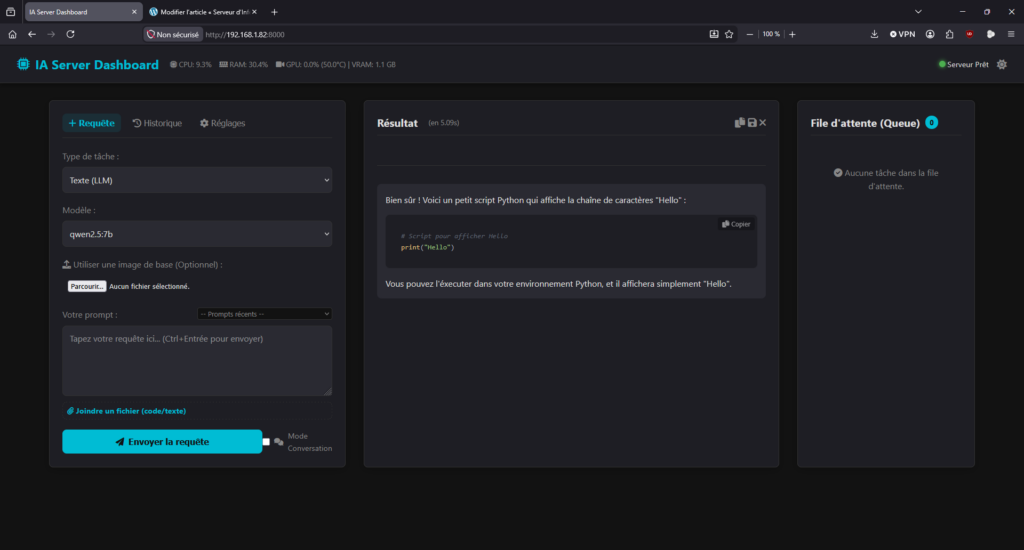
Le Serveur IA embarque un tableau de bord web complet. Il vous permet de lancer des tâches, de surveiller la santé du serveur et de consulter l’historique sans avoir à écrire la moindre ligne de code.
Vous pouvez accéder à l’interface depuis n’importe quel appareil sur votre réseau local (LAN) en tapant l’adresse IP de l’ordinateur hébergeant le serveur, suivie du port 8000 (ex: http://192.168.1.135:8000).
1. Barre de Statut et Surveillance en Temps Réel
En haut de l’écran, un bandeau de statut vous permet de monitorer la « santé » du serveur et de la file d’attente à la seconde près :
- CPU / RAM : Utilisation globale du processeur et de la mémoire vive de la machine. Si le matériel le permet, la température du processeur est affichée.
- VRAM / GPU : Utilisation de la puce graphique et de sa mémoire (indispensable pour surveiller la charge lors de la génération d’images).
- Thème (☀️/🌙) : Un bouton à droite permet de basculer instantanément entre le mode clair et le mode sombre. Votre préférence est mémorisée.
- Tâches en attente & Worker : État actuel du moteur d’IA (
Idle= inactif,Processing= travail en cours).
2. Onglet « Générateur » (Lancer une tâche)
C’est l’interface principale. Elle s’adapte intelligemment selon que vous souhaitez générer du texte ou une image.
Génération de Texte (LLM)
- Choisissez le modèle désiré (la liste est dynamiquement récupérée depuis Ollama).
- Tapez votre requête (prompt). Vous pouvez utiliser le raccourci clavier
Ctrl + Entréepour l’envoyer rapidement. - Joindre un fichier (Code/Texte) : Grâce à l’icône « trombone » ou par simple Glisser-Déposer (Drag & Drop) depuis votre bureau vers la zone de texte, vous pouvez intégrer le contenu d’un fichier
.py,.js,.txt, etc. directement dans votre prompt ! Idéal pour demander une analyse de code. - Vision (Image-to-Text) : Vous pouvez optionnellement uploader une image de base via le bouton dédié. Si le modèle choisi supporte la vision (ex:
llava), il pourra l’analyser. - Mode Conversation : En cochant la case « Mode Conversation », le serveur gardera en mémoire tout votre historique de discussion et l’enverra au modèle à chaque nouvelle question pour préserver le contexte. Attention, un très long contexte consomme plus de tokens !
Génération d’Images (Stable Diffusion)
- Choisissez le modèle (ex:
Dreamshaper). - Upload d’image (Image-to-Image) : Uploadez une ébauche ou une photo pour que l’IA la transforme selon votre texte.
- Options Basiques : Réglez le niveau de qualité (nombre d’étapes de calcul).
- Options Avancées : Force de modification (Strength), Résolution (Largeur/Hauteur) et Seed.
Affichage du Résultat
Dès l’envoi, l’interface vous indique votre position dans la file d’attente et le temps d’attente estimé (environ 15s par tâche précédente).
Dès que la tâche est terminée, le résultat s’affiche sous forme de texte riche :
- Coloration Syntaxique : Le code source généré par l’IA est automatiquement mis en évidence avec un thème sombre (atom-one-dark) pour être facile à lire.
- Actions Rapides : Des boutons permettent de « Copier » le code en un clic, ou de télécharger la réponse complète dans un fichier
.txt.
3. Onglet « Historique »
Le serveur IA enregistre absolument toutes les requêtes (qu’elles viennent de l’interface web ou de vos scripts Python automatisés).
Cet onglet permet de revoir les anciennes tâches :
- Une liste claire et colorée (Vert = Succès, Rouge = Échec).
- Favoris (⭐) : Vous pouvez cliquer sur l’étoile à côté d’une tâche pour l’ajouter à vos favoris. Cela évite qu’elle ne soit supprimée lors des purges de maintenance.
- En cliquant sur une tâche, vous rouvrez le détail complet dans le panneau central (Modèle utilisé, Prompt exact, Résultat, Date et Temps de traitement).
4. Onglet « Paramètres » (Maintenance)
[!NOTE]
Les paramètres modifiés ici sont sauvegardés dans la base de données SQLite et persistent après le redémarrage du serveur.
- Nettoyage automatique (Rétention des Images) : Pour éviter de saturer votre disque dur avec les images générées. Par défaut, les images vieilles de plus de 7 jours sont supprimées au démarrage.
- Purger le Cache (Bouton Rouge) : Permet de supprimer instantanément toutes les anciennes générations et de nettoyer les images associées, à l’exception de celles que vous avez marquées comme favorites (⭐).
Documentation de l’API du Serveur IA
Le serveur IA met à disposition une API REST robuste et une file d’attente (gérée par base de données) pour traiter des requêtes textuelles (LLM) et des générations/traitements d’images (Stable Diffusion).
Cette documentation explique comment interagir programmatiquement avec ce serveur depuis un script Python, sans modifier le serveur lui-même.
Le Client Python Fourni (ai_client.py)
Le serveur est livré avec un client Python prêt à l’emploi (ai_client.py) qui encapsule toute la logique de requêtage, de file d’attente (polling) et d’upload.
1. generate_text : Génération de texte simple
Permet de générer du texte. Bloque l’exécution jusqu’à ce que la tâche soit terminée et retourne la chaîne de caractères générée.
Vous pouvez également passer une liste chat_history pour donner de la mémoire contextuelle au modèle.
Exemple d’utilisation :
from ai_client import LocalAIClient
client = LocalAIClient(endpoint="http://127.0.0.1:8000")
# Exemple avec historique
historique = [
{"role": "user", "content": "Je m'appelle Alice."},
{"role": "assistant", "content": "Bonjour Alice !"}
]
print("Demande envoyée au LLM...")
reponse = client.generate_text(
model="llama3:latest",
prompt="Quel est mon nom ?",
chat_history=historique,
system="Tu es un assistant utile.",
max_tokens=-1, # -1 = illimité
temperature=0.7
)
print("\n--- Réponse du modèle ---")
print(reponse)2. generate_image : Génération d’image (Text-to-Image)
Permet de générer une image à partir d’un prompt. Bloque l’exécution et retourne le chemin d’accès local vers l’image générée (sur le serveur).
Si votre script ne tourne pas sur la même machine que le serveur, vous pouvez utiliser la méthode download_image pour la rapatrier via HTTP.
Exemple d’utilisation :
from ai_client import LocalAIClient
client = LocalAIClient(endpoint="http://127.0.0.1:8000")
print("Génération de l'image en cours...")
image_path_serveur = client.generate_image(
model="Lykon/dreamshaper-8-lcm",
prompt="A futuristic military drone flying over a neon city, highly detailed, 4k",
width=768,
height=512
)
print(f"\nImage générée avec succès sur le serveur : {image_path_serveur}")
# Rapatrier l'image sur notre propre machine
image_locale = client.download_image(image_path_serveur, destination_path="C:/mon_projet/drone_resultat.png")
print(f"L'image a été téléchargée sur votre machine ici : {image_locale}")3. upload_image et Vision (Image-to-Text)
Permet d’envoyer une image locale vers le serveur pour qu’un modèle de vision (comme llava) l’analyse.
Exemple d’utilisation :
from ai_client import LocalAIClient
client = LocalAIClient(endpoint="http://127.0.0.1:8000")
# 1. On upload d'abord le fichier
print("Upload de l'image...")
chemin_serveur = client.upload_image("C:/mon_projet/photo_suspecte.jpg")
# 2. On demande au LLM d'analyser ce fichier
print("Analyse de l'image par l'IA...")
analyse = client.generate_text(
model="llava",
prompt="Décris en détail ce qui se trouve sur cette image.",
init_image_path=chemin_serveur # <-- On passe le chemin renvoyé par l'upload
)
print("\n--- Analyse ---")
print(analyse)4. upload_image et Modification (Image-to-Image)
Permet de transformer une image existante à l’aide d’un modèle d’image en utilisant le paramètre strength.
Exemple d’utilisation :
from ai_client import LocalAIClient
client = LocalAIClient(endpoint="http://127.0.0.1:8000")
print("Upload du croquis...")
chemin_serveur = client.upload_image("C:/mon_projet/croquis_brouillon.png")
print("Transformation du croquis en rendu réaliste...")
image_finale = client.generate_image(
model="Lykon/dreamshaper-8-lcm",
prompt="A photorealistic rendering of a modern tactical vehicle, military green, highly detailed",
init_image_path=chemin_serveur,
strength=0.8 # 0.8 = on modifie beaucoup le croquis d'origine
)
print(f"\nRendu final disponible ici : {image_finale}")5. get_queue_status : Surveiller le serveur
Permet de savoir combien de tâches sont en attente et si le processeur/GPU est actuellement occupé.
Exemple d’utilisation :
from ai_client import LocalAIClient
client = LocalAIClient(endpoint="http://127.0.0.1:8000")
statut = client.get_queue_status()
print(f"Tâches en attente : {statut['pending_tasks']}")
print(f"État du travailleur : {statut['worker_status']}") # 'idle' ou 'processing'
if statut['pending_tasks'] > 5:
print("Alerte: Le serveur IA est très sollicité en ce moment.")6. Gestion du Cache et des Favoris (Nouveau !)
Le client vous permet d’interagir avec la base de données interne pour marquer des tâches comme favorites ou nettoyer les données orphelines.
Exemples :
from ai_client import LocalAIClient
client = LocalAIClient(endpoint="http://127.0.0.1:8000")
# Mettre une tâche en favori (toggle)
is_fav = client.toggle_favorite("mon_task_id_123")
if is_fav:
print("Tâche ajoutée aux favoris !")
# Purger toutes les tâches et images qui ne sont pas en favori
result = client.purge_cache()
print(result["message"]) # Affiche le nombre d'éléments supprimés7. Requêtes Asynchrones (submit_task et delete_task)
Les méthodes generate_* précédentes bloquent le script Python jusqu’à la fin du calcul. Si vous voulez lancer une tâche en arrière-plan sans bloquer votre script, utilisez submit_task.
Exemple d’utilisation :
import time
from ai_client import LocalAIClient
client = LocalAIClient(endpoint="http://127.0.0.1:8000")
# 1. On soumet la tâche (retourne immédiatement)
parametres = {
"prompt": "Génère un rapport de 3 pages sur...",
"max_tokens": 2000
}
task_id = client.submit_task("llm", "llama3:latest", parametres)
print(f"Tâche {task_id} envoyée. Je peux faire autre chose en attendant...")
# 2. Le script peut continuer de faire d'autres opérations
print("Le script principal continue de tourner...")
time.sleep(2)
# 3. Supposons qu'on veuille annuler la tâche
print("Annulation de la tâche...")
succes = client.delete_task(task_id)
if succes:
print("Tâche supprimée avec succès de la file d'attente.")
else:
print("Impossible de la supprimer (elle est probablement déjà terminée ou en cours de traitement).")Guide d’Architecture et Développeur
Ce document s’adresse aux développeurs qui souhaitent comprendre le fonctionnement interne du Serveur IA, le modifier, ou y ajouter de nouvelles fonctionnalités (nouveaux modèles, nouveaux types de tâches).
1. Vue d’ensemble du système
Le serveur est construit autour d’une architecture asynchrone producteur/consommateur pour éviter de bloquer l’API web pendant que la carte graphique (ou le processeur) calcule des résultats lourds.
Les briques principales :
- Client (Frontend / SDK) : Envoie des requêtes REST (JSON) ou uploade des fichiers (multipart/form-data).
- FastAPI (
main.py) : Le routeur principal. Il valide les données (via Pydantic), gère l’upload, et enregistre la tâche en base de données avec le statutpending. Il ne fait aucun calcul d’IA. - Base de données (
database.py& SQLite) : Agit comme une file d’attente persistante. Chaque tâche possède un ID, un type, des paramètres JSON, et un statut (pending,processing,completed,failed). - Le Worker (
worker.py) : Tourne dans un processus séparé (multiprocessing). Il scrute la base de données en permanence à la recherche de la tâchependingla plus ancienne, passe son statut enprocessing, et la confie au pipeline. - La Pipeline d’IA (
models_pipeline.py) : Contient la logique d’exécution propre aux modèles. C’est ici quediffusersourequests(vers Ollama) sont appelés.
2. Structure des fichiers
iaserver/
│
├── main.py # Point d'entrée FastAPI, définitions des routes API
├── worker.py # Boucle infinie scrutant la BDD pour exécuter les tâches
├── models_pipeline.py # Logique métier des modèles d'IA (Ollama, Stable Diffusion)
├── database.py # Modèles SQLAlchemy (Tasks, Settings) et auto-migrations
├── schemas.py # Modèles Pydantic pour la validation des données d'API
├── config.py # Variables de configuration (Ports, IPs, Modèles disponibles)
├── ai_client.py # SDK Python fourni pour attaquer l'API
│
├── client/ # Interface Web (Frontend)
│ ├── index.html # Structure de la page
│ ├── app.js # Logique applicative (Polling, Drag&Drop, DOM)
│ └── style.css # Styles (Thèmes clair/sombre)
│
└── saves/ # Dossier généré automatiquement pour les images
└── uploads/ # Fichiers sources envoyés par l'utilisateur (ex: Image-to-image)3. Comment ajouter un nouveau type de tâche ?
Imaginons que vous souhaitiez ajouter de la génération audio (Text-to-Speech) :
- Mettre à jour
schemas.py:
DansTaskSubmitRequest, letask_typepourra désormais accepter"tts". Ajoutez les paramètres spécifiques (ex:voice,speed) dansTaskParameters. - Créer la méthode dans
models_pipeline.py:
Ajoutez une méthode dansBaseModelPipeline, par exempledef run_tts(self, parameters):.
Implémentez-y le code d’inférence (ex: avecpyttsx3ou le modèleBarkd’HuggingFace). La fonction doit retourner un dictionnaire avec le chemin du fichier audio généré. - Mettre à jour
worker.py:
Dans la méthodeprocess_task, ajoutez une condition :
elif task.task_type == "tts":
result = pipeline.run_tts(params)- Mettre à jour le Frontend (
client/index.html&client/app.js) :
Ajoutez une option<option value="tts">Texte vers Audio</option>dans le selecteur HTML. Mettez à jour le Javascript (renderResult()) pour afficher un lecteur<audio>quandtask_type === "tts".
4. Cycle de vie d’une requête
- L’utilisateur clique sur Envoyer.
app.jsfait unPOST /api/v1/tasks. main.pygénère un UUID, crée l’entrée en base (Statut:pending) et retourne l’UUID.- Le navigateur commence à faire un « polling » (interrogation) régulier via
GET /api/v1/tasks/{uuid}. - Le
worker.py(qui tourne en tâche de fond) récupère l’entrée, la passe enprocessing. - La fonction appropriée de
models_pipeline.pyest appelée. Le calcul bloque le worker (mais pas l’API web). - Le calcul se termine. Le
worker.pymet à jour la base avec le résultat (JSON) et le statutcompleted. - Le prochain polling du navigateur récupère le statut
completedet affiche le résultat final à l’écran !
Résolution de Problèmes (FAQ & Troubleshooting)
Héberger et exécuter des modèles d’intelligence artificielle en local demande souvent des ressources matérielles importantes. Ce document liste les problèmes les plus courants et leurs solutions.
1. Problèmes liés aux Modèles LLM (Ollama)
Le serveur indique qu’Ollama est injoignable
- Symptôme : Vos requêtes de texte restent bloquées ou finissent en erreur « Connection Refused ».
- Cause : L’exécutable
ollaman’est pas lancé en arrière-plan. - Solution :
- Ouvrez un terminal et tapez
ollama serve. - Si le port est déjà pris, vérifiez que l’icône Ollama n’est pas déjà présente dans la barre des tâches Windows (en bas à droite) et qu’il n’y a pas d’antivirus/pare-feu qui bloque le port
11434.
« Model not found » lors de l’exécution
- Symptôme : Erreur immédiate indiquant que le modèle (ex:
llama3) n’existe pas. - Cause : Le modèle n’a pas été téléchargé sur votre machine.
- Solution : Ouvrez un terminal et exécutez la commande
ollama pull nom_du_modele(ex:ollama pull llama3).
2. Problèmes liés à la Génération d’Images (Stable Diffusion / Diffusers)
Erreur OOM (Out Of Memory) / CUDA Out of Memory
- Symptôme : La génération d’image crash avec une longue erreur mentionnant
CUDA out of memory. Tried to allocate XXX MiB... - Cause : Votre carte graphique ne possède pas assez de VRAM pour charger le modèle ou générer une image à la résolution demandée.
- Solutions :
- Réduire la résolution : Ne dépassez pas 512×512 ou 768×768.
- Changer de device : Si vous n’avez pas une carte graphique Nvidia puissante, le modèle doit tourner sur le processeur (CPU). Par défaut,
models_pipeline.pydétecte automatiquementcuda. Si votre GPU est trop faible (ex: moins de 6 Go de VRAM), forcez le calcul sur CPU en modifiant le fichiermodels_pipeline.py: remplacezself.device = "cuda" if torch.cuda.is_available() else "cpu"parself.device = "cpu". Attention, ce sera plus lent !
L’image met énormément de temps à générer (plusieurs minutes)
- Cause : Le calcul se fait sur le CPU (processeur) au lieu du GPU (carte graphique).
- Solution : Vérifiez que vous avez bien installé la version de PyTorch compatible avec CUDA.
Exécutez dans votre environnement :pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118(adaptez l’URL selon votre version de CUDA installée).
Disque dur saturé (Poids des modèles HuggingFace)
- Symptôme : Vous manquez subitement de dizaines de Gigaoctets sur votre disque système (Lecteur C:).
- Cause : La bibliothèque
diffuserstélécharge les modèles (qui pèsent de 2 à 10 Go chacun) et les met en cache. - Solution : Sur Windows, videz le dossier de cache situé par défaut dans
C:\Users\VOTRE_NOM\.cache\huggingface\hub.
3. Problèmes liés au Serveur (Base de données / API)
« Database is locked » (Erreur SQLite)
- Symptôme : Le terminal du serveur affiche une erreur
sqlite3.OperationalError: database is locked. - Cause : L’API (main.py) et le Worker (worker.py) essaient d’écrire en même temps dans la base
tasks.db. - Solution : Bien que le mode WAL (Write-Ahead Logging) soit activé pour limiter cela, si cela arrive, redémarrez simplement le serveur (
Ctrl+Cpuis relancezpython main.py).
Port 8000 déjà utilisé
- Symptôme : Uvicorn refuse de démarrer avec l’erreur
[Errno 10048] error while attempting to bind on address ('0.0.0.0', 8000). - Cause : Un autre serveur ou logiciel utilise déjà le port 8000.
- Solution : Modifiez le fichier
config.pyet changez la lignePORT = 8000parPORT = 8080(ou un autre nombre). N’oubliez pas d’indiquer ce nouveau port si vous utilisez le client Python !